软件性能工程 「Software Performance Engineering」
本文使用不到五分钟的阅读时间来阐述软件性能工程里的关键知识点,有助于大家在规划软件项目时,通过引入性能工程以提高软件项目的可用性与市场成功率。简单来说,软件性能工程是通过将性能指标维度纳入到软件开发周期中的各关键节点,通过事前规划与各里程碑节点上的关键验收,来追求最终交付的软件质量是符合设计预期的。
它的价值在哪里?
在开发软件时(不包含简单的脚本类程序),有时候会优先考虑把功能做完,即所谓的Make it run first。此时大部分的精力都放在了功能开发上,对性能指标的考虑是放在第二,甚至第三位的。有时候甚至不考虑性能,只有当客户反馈了问题之后才会着手去优化代码。
这种做事方法就不是一个工程师思维的做事方式,更像是产品经理的思维。先把东西弄出来,试一试,看看效果怎么样。这种是在小规模,或者影响可控的范围内是可行的,但这并不是常态。更常见的情况是,工程师根据比较明确的需求通过项目管理(如敏捷开发)的方式进行工程开发,为了使交付效率与质量最高,必须遵照一定的工程化方式做事情。性能工程能帮助项目解决的难题如下:
- 可避免性能瓶颈是因软件架构引起的问题,这是典型的低概率但后果严重的错误。一旦遇到这类问题,通过优化几处热点代码是无法根治的,需要彻底的重构。
- 用户反馈的问题无法通过有效的手段、日志来定位问题,只能通过成本最高的方式,也就是让用户复现问题的方式来定位问题。
- 硬件容量规划时无法根据之前的项目经验进行量化分析。
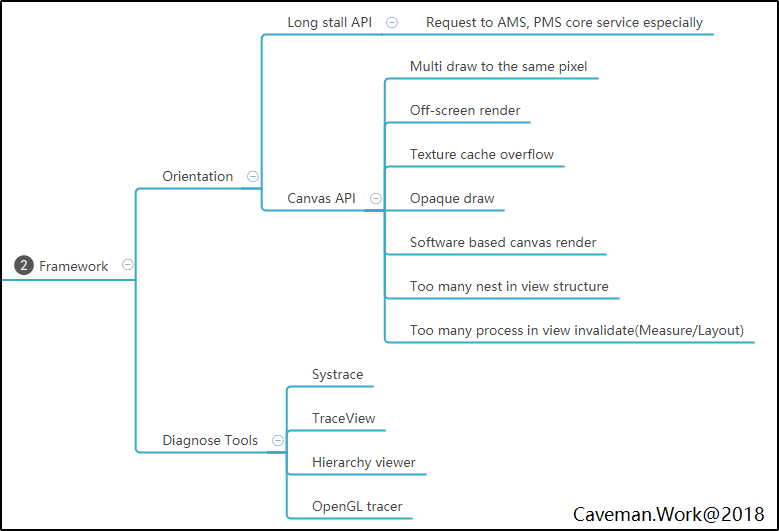
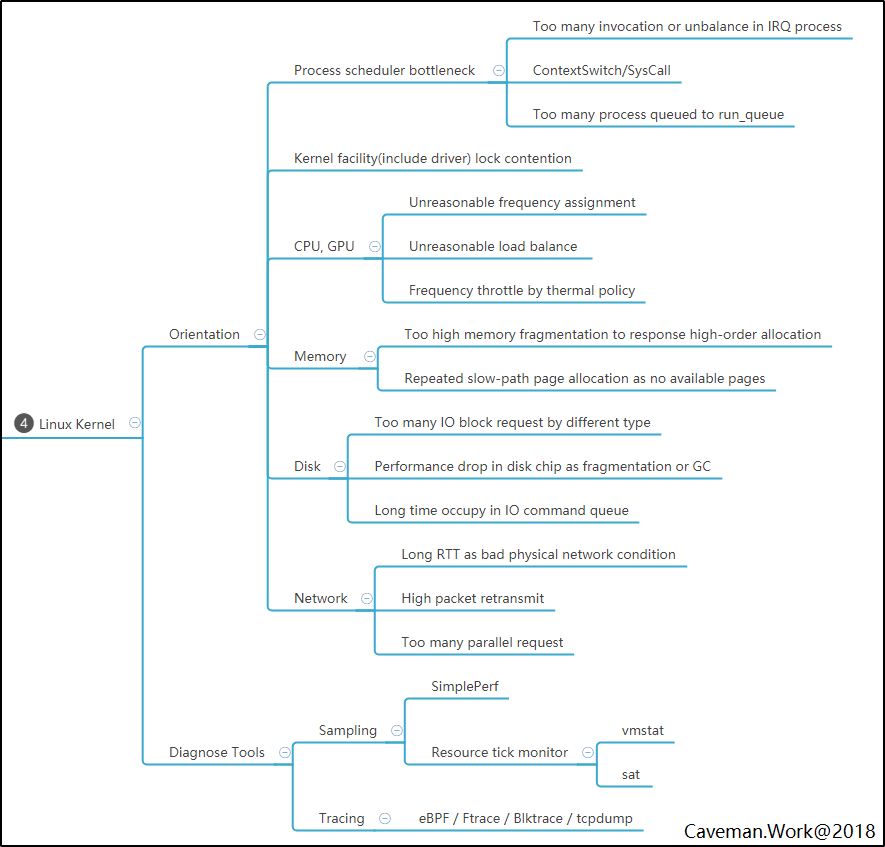
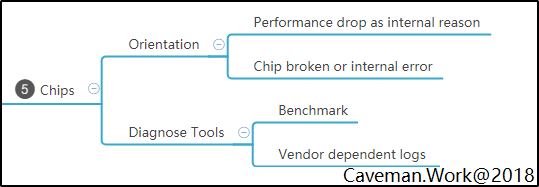
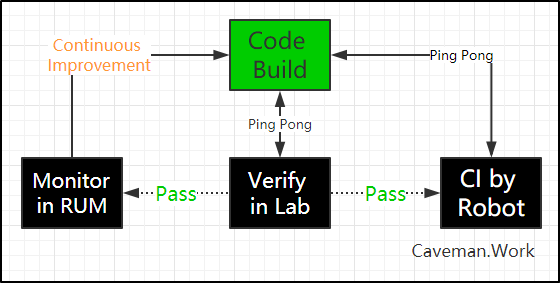
SPE Lite版执行流程
具体怎么执行呢?性能工程是一个完整的工程学科,这篇短文当然无法完整的描述所有的细节,所有的知识点。就着够用就好的原则,仅介绍最关键的执行步骤,读者可感受下画风。
- 通过用户调研与竞品分析,定义关键用户性能指标,如:吞吐量,传输速度,界面刷新帧率
- 设计可满足业务需求与性能指标的软件架构
- 对性能指标建模
- 如果是排队系统时,使用排队论建模工具
- 开发性能指标测试工具与测试用例
- 开发用于记录性能指标变化的监控器
- 制定性能数据本地存储规则
- 制定性能数据云端回传规则
- 制作性能数据可视化表盘
写在最后
- 做事讲究方法,套路。这些方法,用现在的话来说就是各种思维模式。
- 从之前火热的互联网思维,到近几年流行的产品思维,本质上都是做事方式,其目的也非常简单,那就是更好地做事。
- 通过更好地做事,才有可能做出优秀的产品,只有优秀产品才有可能提高市场竞争力。当产品有了市场竞争力,才有可能赢得其他方面的成功,比如商业。

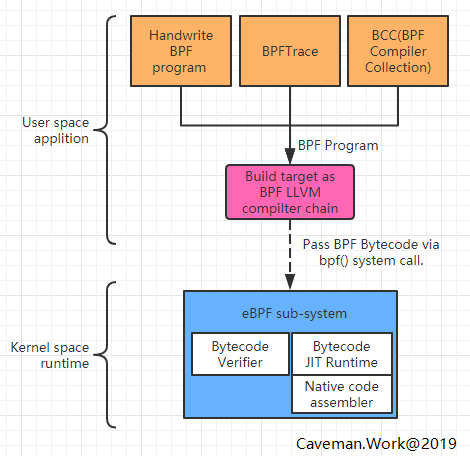

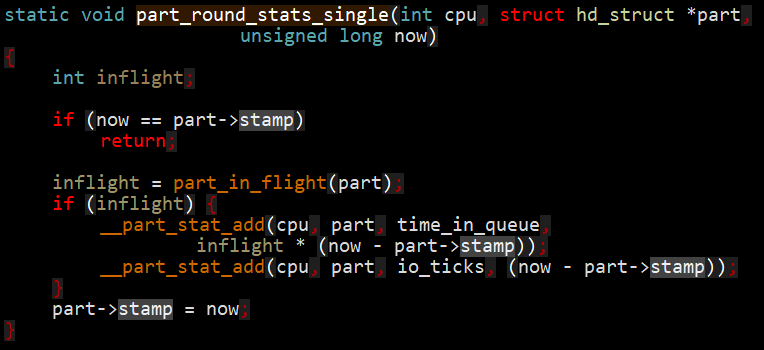


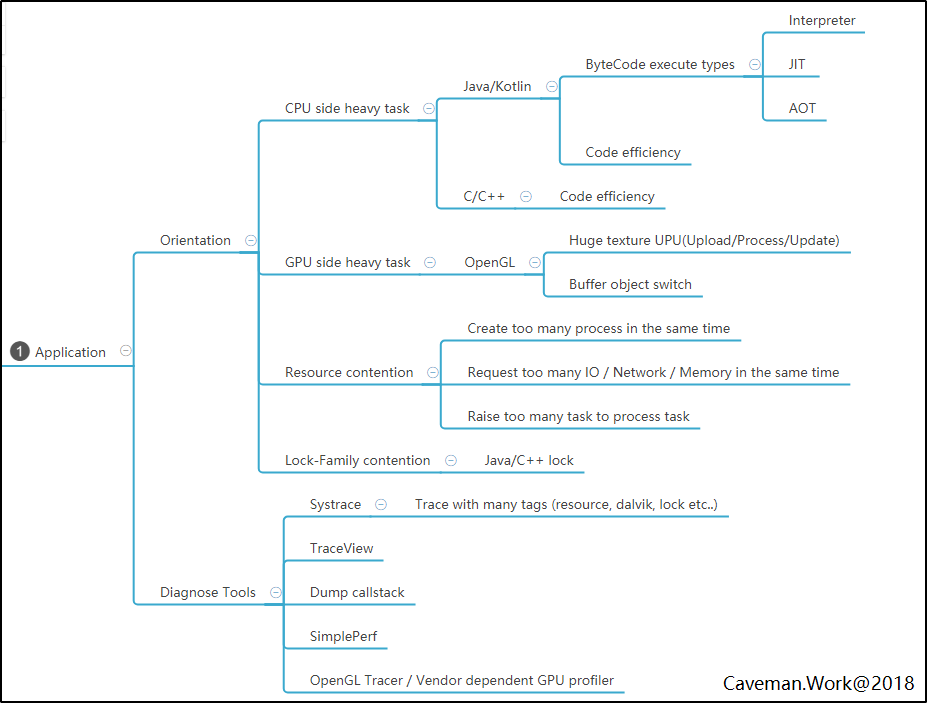



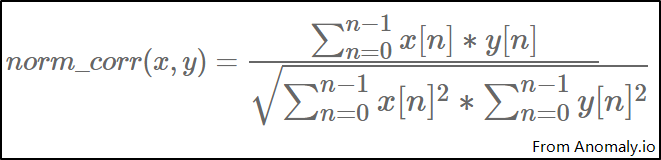



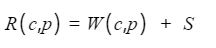
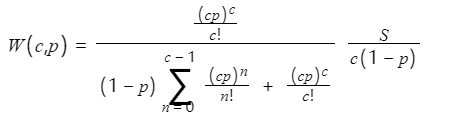
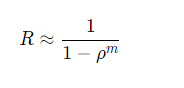
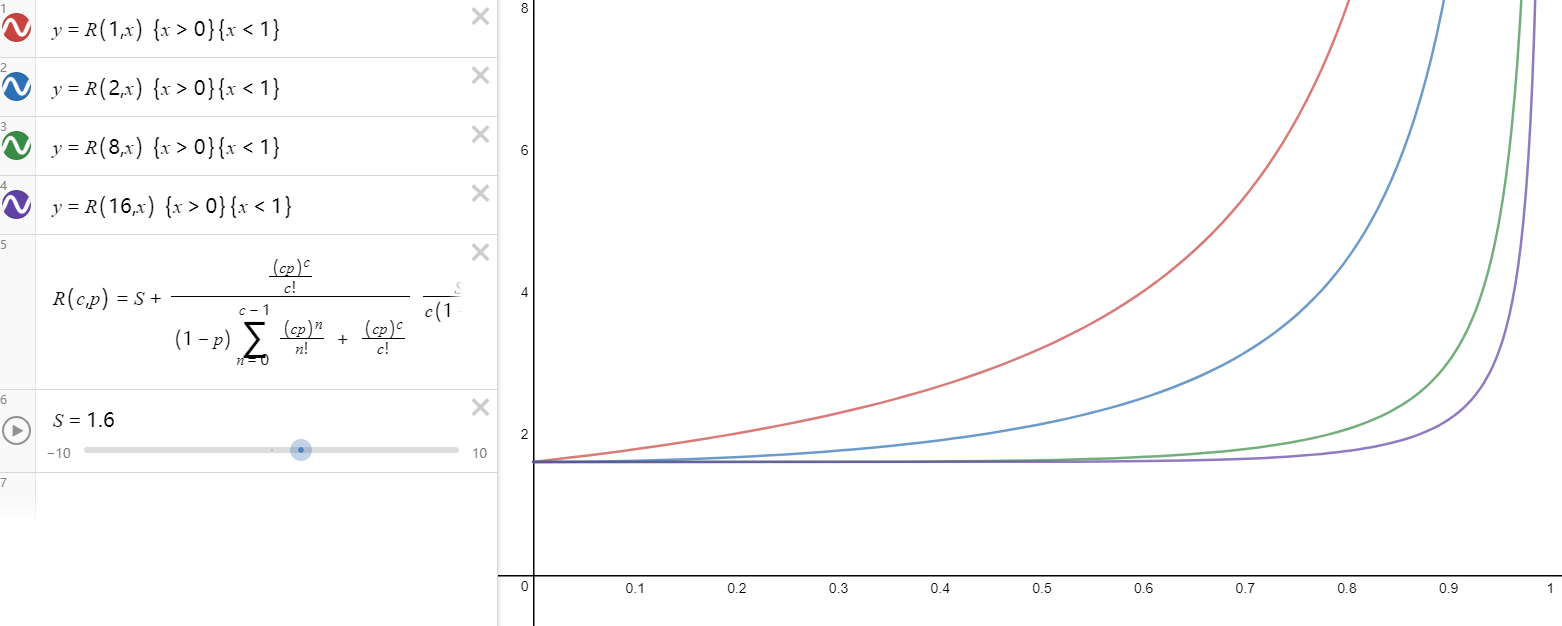
与其衍生法则的应用/queue_system.png)
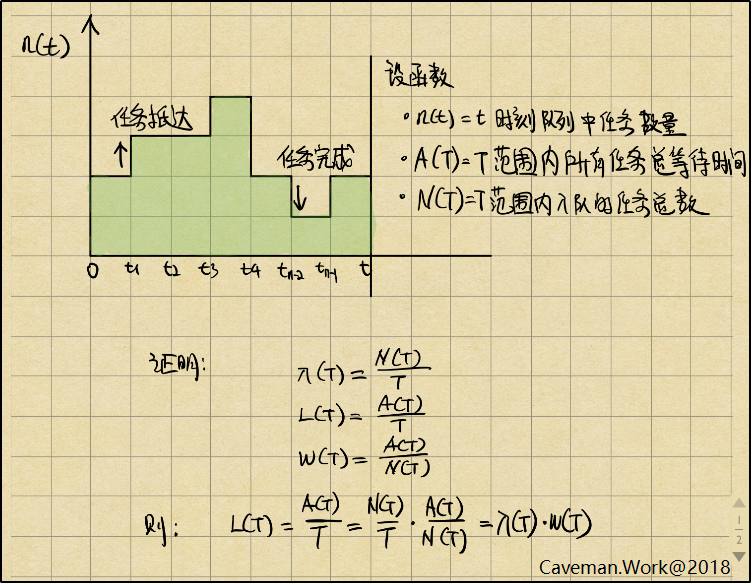
与其衍生法则的应用/little_law_proof.png)